
之前在执行脚本时发现一个问题:
|
|
|
|
对于加eval和不加eval处理的./c.sh $OPTS命令结果是不一样的,而且直接的./c.sh $OPTS得出的并不是我们想要的结果:
为了说明这个问题,我研究了一下bash命令行处理的流程,为什么会出现这种差别,以下分为两步来说明:
(1)说明bash命令行处理流程;
(2)使用grep命令+log打印+gdb+xcode来重新调试源码,从源码里解释流程。
在这里贴出官方源码下载地址,此处我使用的版本是bash4.4
首先来说一下bash命令行处理流程,分为12步,来自《学习bash》这本书中,流程图如下: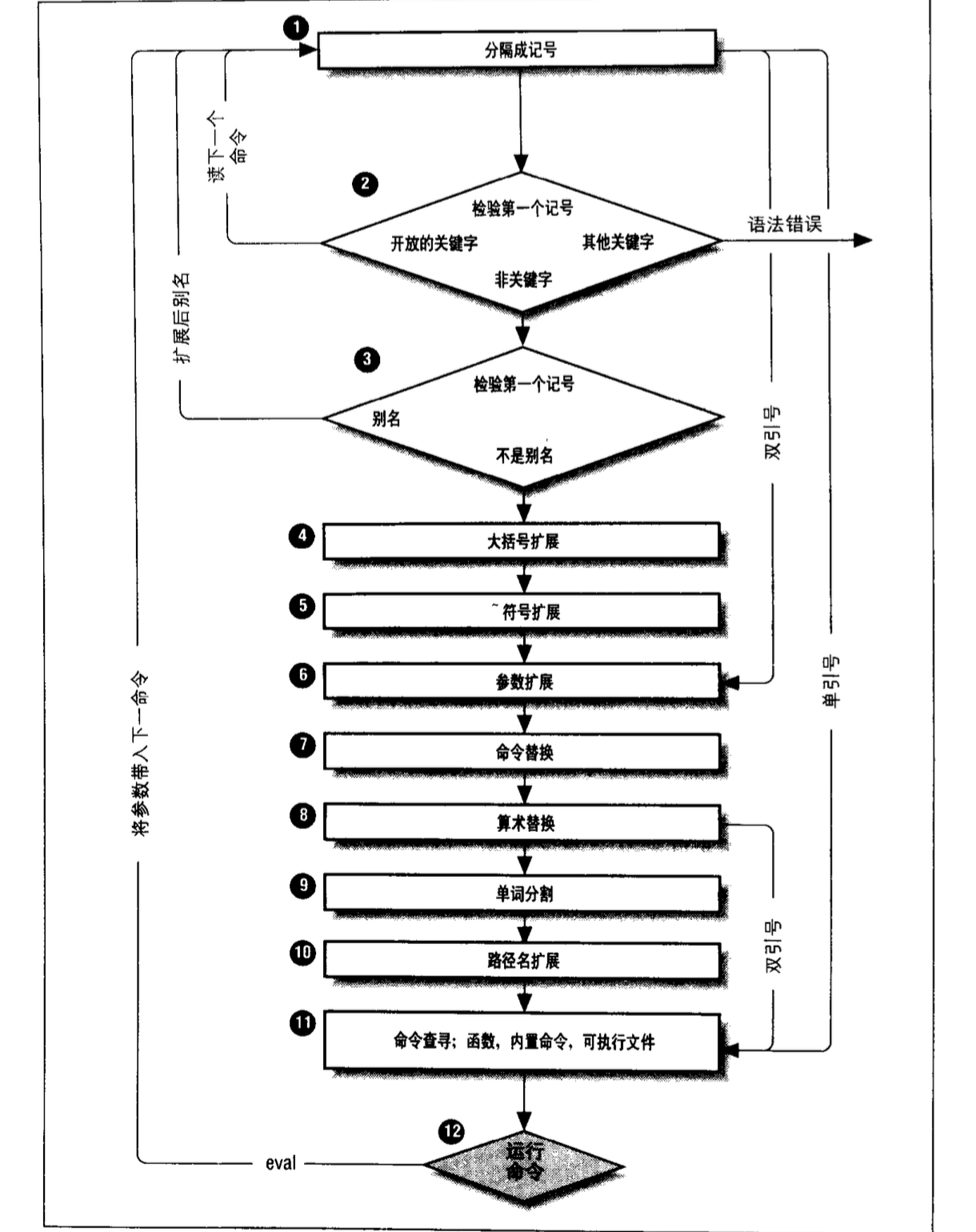
对于一行bash命令的执行流程分为两大步骤:解析和执行。
解析的作用是获得用于执行的命令结构体:COMMAND *global_command
执行主要是针对特定类型的命令进行执行和结果处理,我们主要看解析过程。
解析
bash的入口函数main()位于文件shell.c中
main函数前部分主要做初始化工作,初始化完成之后,进入eval.c中的交互循环函数reader_loop()(shell.c中799行)。该函数不断读取和执行命令,直到遇到EOF。
此时函数调用关系为:main()–>reader_loop()。
|
|
reader_loop()函数中调用read_command()取得命令结构体global_command,然后赋值给current_command并交给execute_command ()去执行。
read_command ()调用parse_command (),此时函数调用关系为:main()–>reader_loop()–>read_command()–>parse_command()
|
|
parse_command()调用y.tab.c中的yyparse ()函数,并使用函数gather_here_documents ()处理here document类型的输入重定向。
yyparse ()由YACC通过parse.y生成,函数内使用大量的goto语句,可读性较差:
|
|
函数内调用yylex()(宏定义:#define YYLEX yylex ())来获得并计算出整型变量yyn的值,然后根据不同的yyn值获取具体的命令结构体。
在函数yylex()内部,调用read_token()获得各种类型的token并进一步调用read_token_word()获取具体的不同类型的单词结构WORD_DESC。
之后在yyparse()中,调用文件make_cmd.c中各种函数,根据yylex()获得的各种token和word组装成具体command。
此时的函数调用关系为:
main()–>reader_loop()–>read_command()–>parse_command()–>yyparse()–>yylex()–>read_token()——>read_token_word()————>global_command
下边来举个例子例1,这是我在下载的bash源码中添加了printf编译后的一个简单命令执行的输出,其中的每个名词都是源码里的函数名,如果需要找到所在文件,我们可以使用grep命令,例如grep -n “reader_loop” *(其中-n代表标出所在行数,*代表在该文件夹下的所有文件中查找,更详细的grep用法大家可以查看linux shell编程指南):
上边的输出基本对应12步处理流程,接下来我们具体深入分析:
首先看两个执行结果:
脚本内容:
执行结果如下:
脚本内容:
|
|
执行结果如下:
|
|
这里第一个脚本未对双引号进行处理,为什么呢?
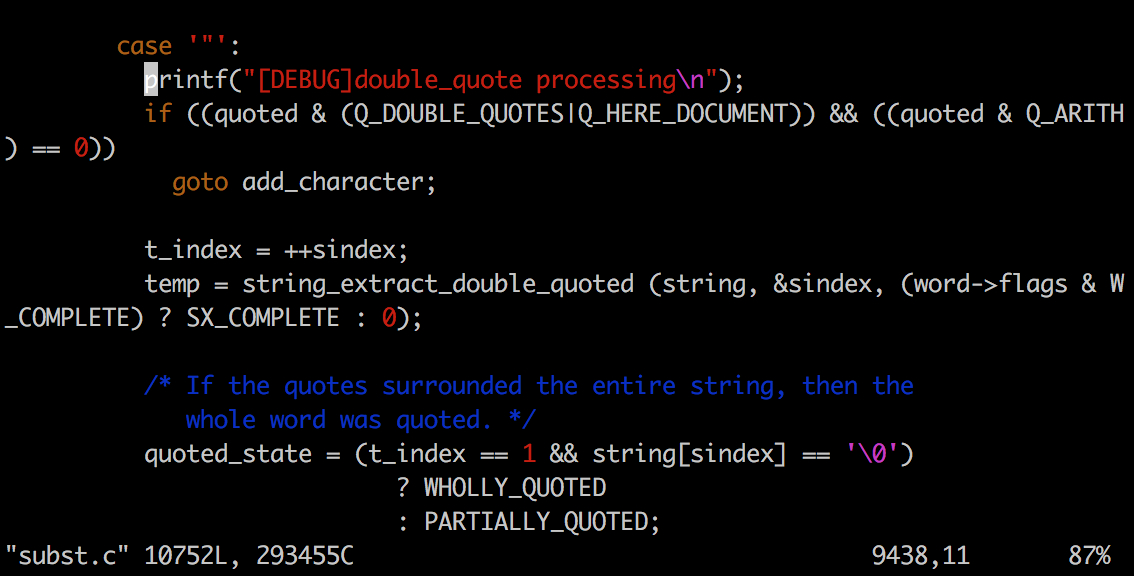
出现这种不同,主要是在于命令行处理流程中对于双引号的处理位置。在命令行处理流程中,位于subst.c文件9017(大约位置,因为加log信息后有变)处的函数 expand_word_internal()是处理从第五步波浪号扩展到第八步算术替换的核心函数,而实际对于双引号的处理是在与这几步变换并列的一个switch语句里,bash在处理完$相关的扩展之后会直接跳出switch,所以就跳过了关于双引号的处理,也就是说switch语句里case的顺序是$符号的相关扩展在前,双引号处理的在后。
至于我是如何找到的呢,在这里也贴出来供大家参考,少走弯路:
在例1中我们可以看到根据log信息我们已经发现了双引号处理的函数是string_extract_double_quoted,那么我们接下来要做的就是找到string_extract_double_quoted()函数是如何从read_loop()函数一路被调用的,所以现在我们使用gdb,调试命令如下:(当前我们在bash-4.4文件夹下,a.sh相对路径bash-4.4/task/a.sh)
接下来我们只要用grep命令找到expand_word_internal函数进行具体分析即可:
在subst.c中添加的log信息如下: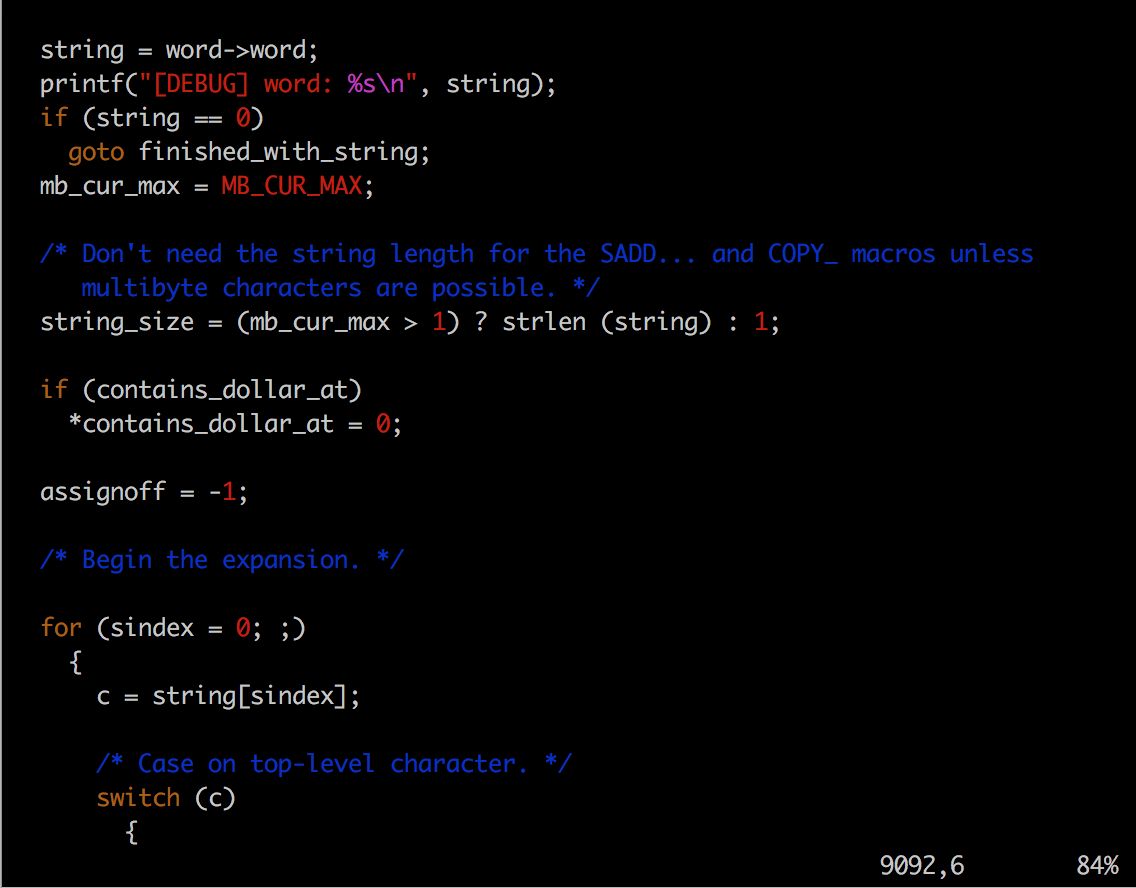
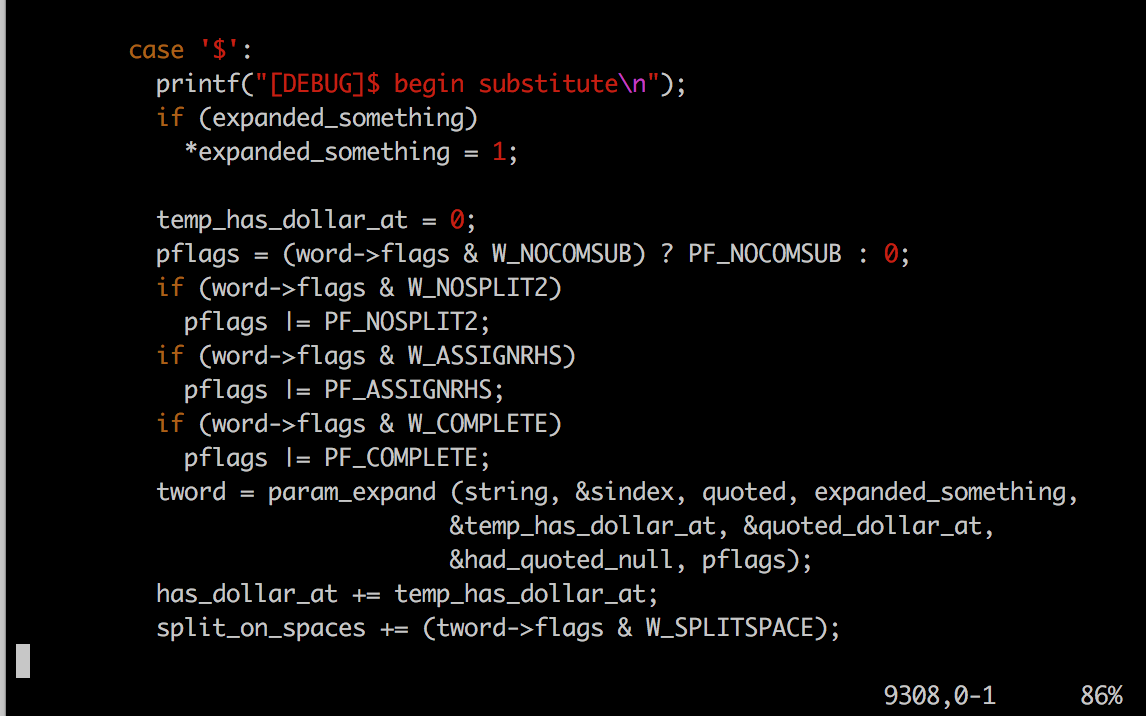
对于./c.sh $OPTS的执行过程中打印:
[DEBUG] word: ./c.sh
[DEBUG] word: $OPTS
[DEBUG]\$ begin substitute //在这里执行\$OPTS的参数扩展
[DEBUG]\$ end substitute
之后直接跳出switch循环了。
而对于./c.sh –conf javaOption=”-Da=b -Dc=d”的执行过程中打印:
[DEBUG] word: ./task/c.sh
[DEBUG] word: –conf
[DEBUG] word: javaOption=”-Da=b -Dc=d”
[DEBUG]double_quote processing //处理双引号
[DEBUG] word: -Da=b -Dc=d
Detaching after fork from child process 14855.
0:{–conf}
1:{javaOption=-Da=b -Dc=d}
在接下来的switch里边会处理到双引号,调用string_extract_double_quoted()函数将引号内字符串处理为一个整体。
写到这里也就差不多结束啦,bash源码的解读还有很多需要研究的地方,目前我还只是因为eval命令的原因研究了bash中关于双引号的处理,以此来作为一个引子,也给各位跟我一样的新手提供一个编译调试,解读源码的完整思路,如果大家有什么问题或者文中有什么错误,还请多多指正,多多交流~

