

String,StringBuilder,StringBuffer区别
运行速度方面,StringBuilder > StringBuffer > String
String最慢的原因:(以下面拼接字符串为例)1234String str="abc";System.out.println(str);str=str+"de";System.out.println(str);
如果运行这段代码会发现先输出“abc”,然后又输出“abcde”,好像是str这个对象被更改了,其实,这只是一种假象罢了,JVM对于这几行代码是这样处理的,首先创建一个String对象str,并把“abc”赋值给str,然后在第三行中,其实JVM又创建了一个新的对象也名为str,然后再把原来的str的值和“de”加起来再赋值给新的str,而原来的str就会被JVM的垃圾回收机制(GC)给回收掉了,所以,str实际上并没有被更改,也就是前面说的String对象一旦创建之后就不可更改了。所以,Java中对String对象进行的操作实际上是一个不断创建新的对象并且将旧的对象回收的一个过程,所以执行速度很慢。
而StringBuilder和StringBuffer的对象是变量,对变量进行操作就是直接对该对象进行更改,而不进行创建和回收的操作,所以速度要比String快很多。
此外,StringBuilder是线程不安全的,而StringBuffer是线程安全的,StringBuffer中很多方法可以带有synchronized关键字,所以StringBuilder最快。
总结:
String:适用于少量的字符串操作的情况StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况
StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
多线程知识总结
创建线程的4种方式:
- 继承Thread类
- 实现Runnable接口
- 使用Executor框架创建线程池
- 实现Callable接口
实现Runnable接口这种方式更受欢迎,因为这不需要继承Thread类。在应用设计中已经继承了别的对象的情况下,这需要多继承(而Java不支持多继承),只能实现接
口。同时,线程池也是非常高效的,很容易实现和使用。
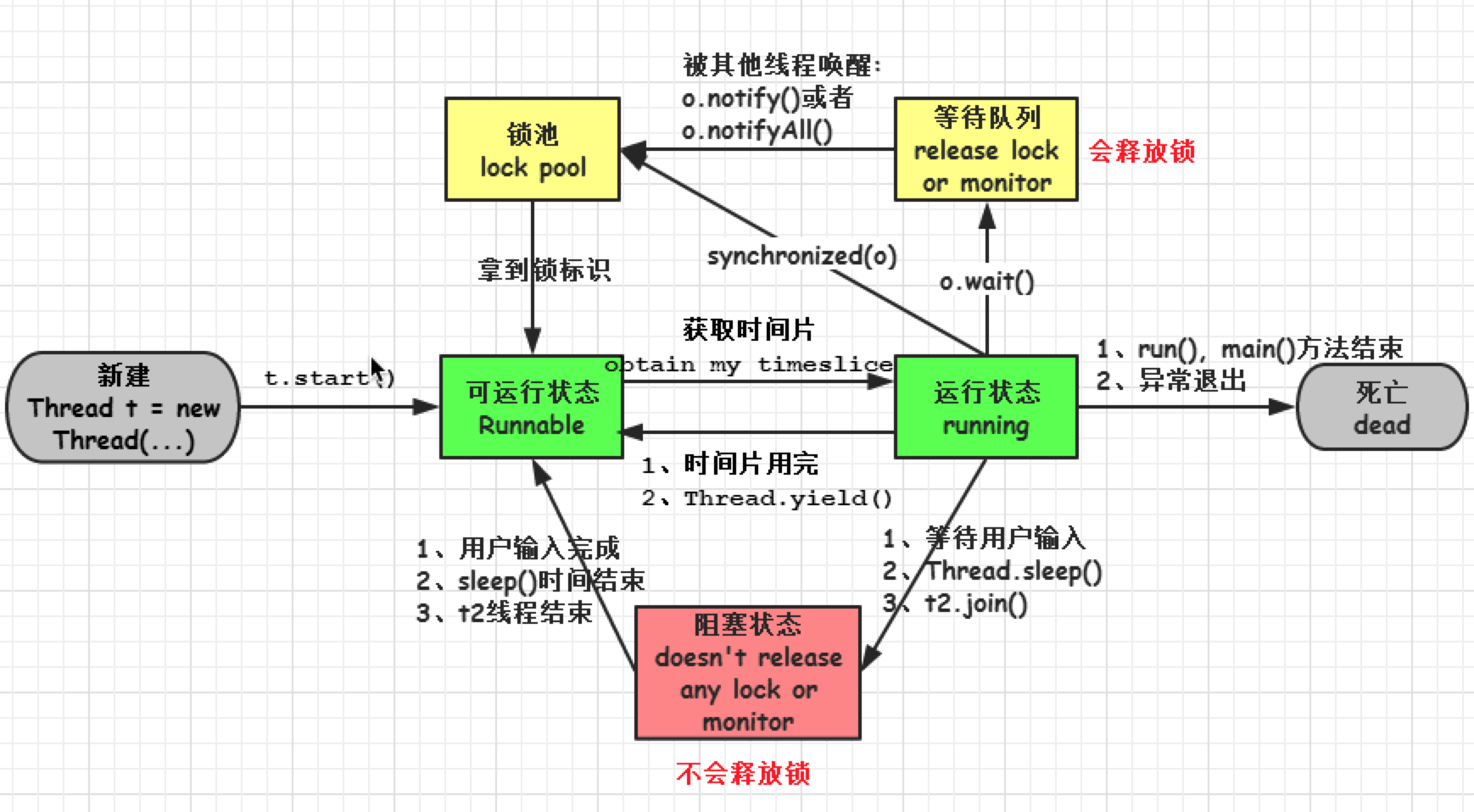
线程的5种状态:
- 新建( new ):新创建了一个线程对象。
- 可运行( runnable ):线程对象创建后,其他线程(比如 main 线程)调用了该对象 的 start ()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获 取 cpu 的使用权 。
- 运行( running ):可运行状态( runnable )的线程获得了 cpu 时间片( timeslice ) ,执行程序代码。
- 阻塞( block ):阻塞状态是指线程因为某种原因放弃了 cpu 使用权,也即让出了 cpu timeslice ,暂时停止运行。直到线程进入可运行( runnable )状态,才有 机会再次获得 cpu timeslice 转到运行( running )状态。阻塞的情况分三种:
(一). 等待阻塞:运行( running )的线程执行 o . wait ()方法, JVM 会把该线程放 入等待队列( waitting queue )中。
(二). 同步阻塞:运行( running )的线程在获取对象的同步锁时,若该同步锁 被别的线程占用,则 JVM 会把该线程放入锁池( lock pool )中。
(三). 其他阻塞: 运行( running )的线程执行 Thread . sleep ( long ms )或 t . join ()方法,或者发出了 I / O 请求时, JVM 会把该线程置为阻塞状态。 当 sleep ()状态超时、 join ()等待线程终止或者超时、或者 I / O 处理完毕时,线程重新转入可运行( runnable )状态。 - 死亡( dead ):线程 run ()、 main () 方法执行结束,或者因异常退出了 run ()方法,则该线程结束生命周期。死亡的线程不可再次复生。
线程池: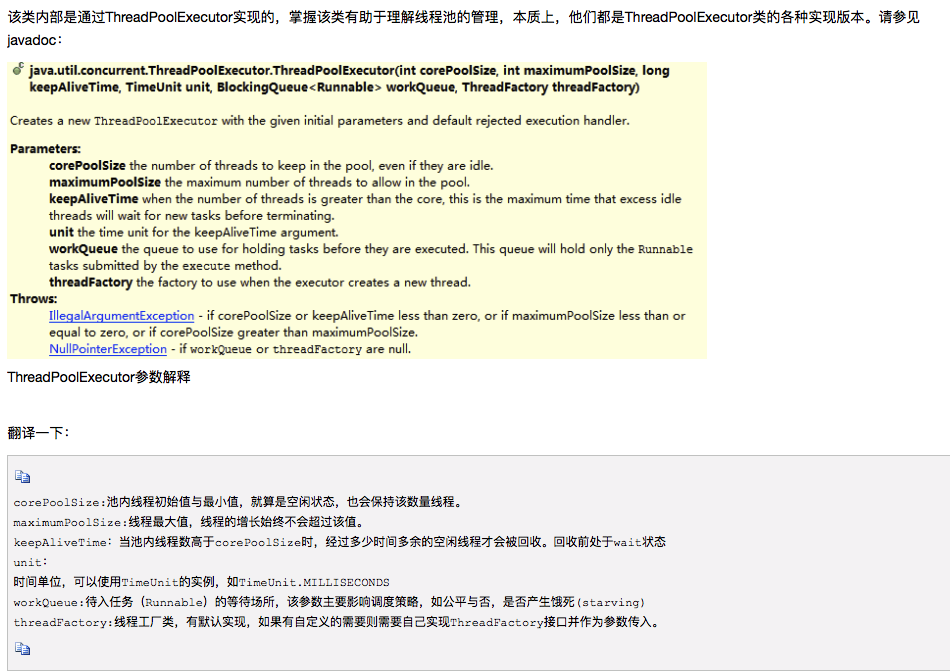
四种常见线程池:
| name | 创建方法 | 参数特征 |
|---|---|---|
| 可缓存线程池CachedThreadPool() | ExecutorService mCachedThreadPool = Executors.newCachedThreadPool(); | new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue |
| 定长线程池FixedThreadPool() | ExecutorService mFixedThreadPool= Executors.newFixedThreadPool(int nThreads); | new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue |
| SingleThreadPool | ExecutorService mSingleThreadPool = Executors.newSingleThreadPool(); | new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue |
| ScheduledThreadPool | ExecutorService m = Executors.newScheduledThreadPool(int corePoolSize); | new ThreadPoolExecutor(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue()) |
进程和线程区别及通信
进程:是具有独立功能的应用程序,它是系统进行资源分配和调度的一个独立单位;线程:线程是进程内部的一个执行单元,是CPU调度和分派的基本单位,线程自己基本上不拥有系统资源。
区别与联系:
- 一个线程只能属于一个进程,一个进程内部可以有多个线程;
- 同一进程的多个线程间共享资源,某进程内的线程在其他进程不可见;
- 进程间切换代价大,线程间切换代价小。
线程间通信方式:
|
|
Java类加载及初始化顺序
加载
1、一般来说,类的代码在初次使用时被加载。通常指创建第一个对象时,或者访问类的static域或static方法时会发生加载。
2、当类加载器开始加载第一个类的过程中如果发现该类具有基类它将继续进行加载,直至所有的基类被加载完成
3、然后根基类的static初始化会被执行,然后是下一个导出类static域,以此类推,直至所有相关类的static域加载初始化完成。
4、至此必要的类都被加载完成,对象可以被创建。注意:基类的加载不管是否进行对象的创建都会被执行。
初始化
5、然后是根基类成员变量按顺序初始化,然后调用根基类构造方法。根基类完成后以相同顺序执行第一个导出类的初始化直至完成对象创建。
通俗来讲,类加载和初始化顺序就是,加载类完成后,先从基类到当前类加载static域,然后从基类到当前类按顺序初始化普通成员变量和普通方法块和构造方法。示例:
|
|
Java中常用参数值
char常用范围:123大写字母(A-Z):65 (A)~ 90(Z) 小写字母(a-z):97(a) ~ 122(z)字符数字('0' ~ '9'):48('0') ~ 57('9')
|
|
JAVA基本类型与封装类型的区别
java有8种基本数据类型:
| 基本数据类型 | 对应封装类型 | 最小值 | 最大值 |
|---|---|---|---|
| byte | Byte | -128(-2^7) | 127(2^7-1) |
| short | Short | -32768(-2^15) | 32767(2^15-1) |
| int | Integer | -2,147,483,648(-2^31) | 2,147,483,647(2^31-1) |
| long | Long | ||
| float | Float | ||
| double | Double | ||
| boolean | Boolean | ||
| char | Character |
1、传递方式不同
基本数据类型(原始数据类型)是值传递,封装类型是引用传递
2、封装类型有方法和属性
可以利用这些方法和属性来处理数据,例如Integer.parseInt(strings);基本数据类型都是final修饰的,不能被继承和扩展新的类、方法
3、默认值不同
如int i;默认值为0,而Integer j;默认值为null,因为此时j为对象,对象默认值为null;
4、存储位置不同
定义的基本数据类型的变量和对象的引用变量(地址)存储在栈中,而实际对应的对象(value)是存储在堆中12int i = 5;//直接在栈中分配空间 Integer i = new Integer(5);//对象是在堆内存中,而i(引用变量)是在栈内存中
JDK5.0开始可以自动封包了,基本数据类型可以自动封装成封装类。
比如集合List,往里添加对象Object,需要将数字封装成封装类型对象,再存到List中12List list=new ArrayList();list.add(new Integer(1));
在JDK5.0 以后可以自动封包,直接写12List list=new ArrayList();list.add(1);
特别注意:
JVM中一个字节以下的整型数据会在JVM启动的时候加载进内存,除非用new Integer()显式的创建对象,否则都是同一个对象
对于==,一般比较引用地址,有基本数据类型的都是比较值,例如Integer xx= int xxx123456789101112131415Integer a = new Integer(10);// 使用new Integer()显式创建对象Integer b = new Integer(10);Integer c = 10; //JVM中一个字节以下的整型数据会在JVM启动的时候加载进内存,除非用new Integer()显式的创建对象,否则都是同一个对象Integer c1 = 10;Integer c2 = 10;Integer d = 130; //超过一个字节,非同一个对象 d!=d1Integer d1 = 130;int e = 10;int f = 10;System.out.print(a==b);//falseSystem.out.print(a==c);//falseSystem.out.print(c==c1 && c==c2);//trueSystem.out.print(d==d1);//falseSystem.out.print(e==f);//trueSystem.out.print(a==e && c==e);//true 对于==,一般比较引用地址,有基本数据类型的都是比较值
JAVA反射
1、什么是反射?
Java反射就是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;并且能改变它的属性。而这也是Java被视为动态(或准动态,为啥要说是准动态,因为一般而言的动态语言定义是程序运行时,允许改变程序结构或变量类型,这种语言称为动态语言。从这个观点看,Perl,Python,Ruby是动态语言,C++,Java,C#不是动态语言。)语言的一个关键性质。
2、反射能做什么?
我们知道反射机制允许程序在运行时取得任何一个已知名称的class的内部信息,包括包括其modifiers(修饰符),fields(属性),methods(方法)等,并可于运行时改变fields内容或调用methods。那么我们便可以更灵活的编写代码,代码可以在运行时装配,无需在组件之间进行源代码链接,降低代码的耦合度;还有动态代理的实现等等;但是需要注意的是反射使用不当会造成很高的资源消耗!
https://www.cnblogs.com/ysocean/p/6516248.html
反射示例:12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182package com.lijingdong.leetcode;import java.lang.reflect.Constructor;import java.lang.reflect.Field;import java.lang.reflect.Method;class Person { //私有属性 private String name = "Tom"; //公有属性 public int age = 18; //构造方法 public Person() { } //私有方法 private void say() { System.out.println("private say()..."); } //公有方法 public void work() { System.out.println("public work()..."); }}public class Test { public static void main(String[] args) throws Exception { Class c2 = Person.class; //获得类完整的名字 String className = c2.getName(); System.out.println(className);//输出com.ys.reflex.Person//获得类的public类型的属性。 Field[] fields = c2.getFields(); for (Field field : fields) { System.out.println(field.getName());//age }//获得类的所有属性。包括私有的 Field[] allFields = c2.getDeclaredFields(); for (Field field : allFields) { System.out.println(field.getName());//name age }//获得类的public类型的方法。这里包括 Object 类的一些方法 Method[] methods = c2.getMethods(); for (Method method : methods) { System.out.println(method.getName());//work wait equals toString hashCode等 }//获得类的所有方法。 Method[] allMethods = c2.getDeclaredMethods(); for (Method method : allMethods) { System.out.println(method.getName());//work say }//获得指定的属性 Field f1 = c2.getField("age"); System.out.println(f1);//获得指定的私有属性 Field f2 = c2.getDeclaredField("name");//启用和禁用访问安全检查的开关,值为 true,则表示反射的对象在使用时应该取消 java 语言的访问检查;反之不取消 f2.setAccessible(true); System.out.println(f2);//创建这个类的一个对象 Object p2 = c2.newInstance();//将 p2 对象的 f2 属性赋值为 Bob,f2 属性即为 私有属性 name f2.set(p2, "Bob");//使用反射机制可以打破封装性,导致了java对象的属性不安全。 System.out.println(f2.get(p2)); //Bob//获取构造方法 Constructor[] constructors = c2.getConstructors(); for (Constructor constructor : constructors) { System.out.println(constructor.toString());//public com.ys.reflex.Person() } }}
运行结果: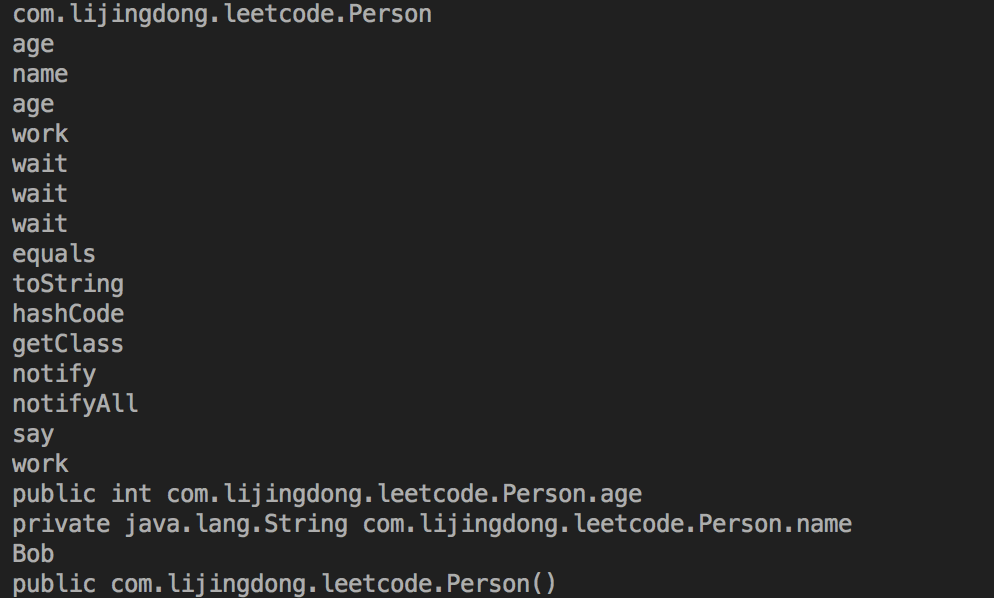
141. Linked List Cycle
Question:
Given a linked list, determine if it has a cycle in it.
idea:
- Use two pointers, walker and runner.
- walker moves step by step. runner moves two steps at time.
- if the Linked List has a cycle walker and runner will meet at some
point.12345678910111213public boolean hasCycle(ListNode head) {if(head==null) return false;ListNode walker = head;ListNode runner = head;while(runner.next!=null && runner.next.next!=null){walker = walker.next;runner = runner.next.next;if(walker==runner){return true;}}return false;}
389. Find the Difference
一般思路:12345678910111213public static char findTheDifference(String s, String t) { int[] map = new int[26]; char c = 97; for(int i=0;i<s.length();i++){ map[s.charAt(i)-'a']++; } for(int j=0;j<t.length();j++){ map[t.charAt(j)-'a']--; if(map[t.charAt(j)-'a']==-1) return t.charAt(j); } return c;}
利用位异或:123456789public static char findTheDifference(String s, String t) { int len = s.length(); char c = t.charAt(len); for (int i = 0; i < len; i++) { c ^= s.charAt(i); c ^= t.charAt(i); } return c; }
缺失模块。
1、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
2、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: true
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true
<font color=#ffffff face="手札体-简" size="5">Name: peanut<br>School: Tsinghua University<br>Mail: peanut7379@gmail.com</font>